Database Internals Reading Notes
Preface
The most significant distinctions between database systems are concentrated around two aspects:
- how they store?
- how they distribute the data?
Storage Engines
The database systems are applications built on top of storage engines, offering a schema, a query language, indexing, transactions, and many other useful features.
Some issues, especially when it comes to performance and scalability, start showing only after some time or as the capacity grows.
Ch1: Introduction and Overview
Three dimensions to classify database systems:
- Memory or Disk based?
- Column or Row oriented?
- OLTP, OLAP, or HTAP?
Memory- VS. Disk-Based DBMS
mem-based pros:
- hight performance
- access granularity
- easily programming
mem-based cons:
- lack of durability
- high costs
disk-based pros:
- easier to maintain
- low costs
durability in memory-based stores: snapshot + log, asynchronously apply log batch to previous snapshot for updating, this process is called checkpointing.
Column- VS. Row-Oriented DBMS
Column-oriented databases should not be mixed up with wide column stores, such as BigTable or HBase.
Data Files and Index Files
Database systems store data records, consisting of multiple fields, in tables, where each table is usually represented as a separate file. There are two types of files: data file and index file.
Files are partitioned into pages, which typically have the size of a single or multiple disk blocks.
Most modern storage systems don’t delete data from pages explicitly. Instead, they use deletion markers (alse called tombstones), which contain deletion metadata, such as a key and a timestamp. Space occupied by the records shadowed by their updates or deletion markers is reclaimed during garbage collection, which reads the pages, writes the live records to the new place, and discards the shadowed ones.
Data files can be implemented as:
- index-organized tables
- heap-organized tables (records are placed in a writer order)
- hash-organized tables
Buffering, Immutability, and Ordering
Most of the distinctions and optimizations in storage structures discussed in this book are related to one of these three concepts.
Ch2: B-Tree Basics
Disk-Based Structures
HDD: the smallest transfer unit is a sector, its size typically range from 512 bytes to 4Kb.
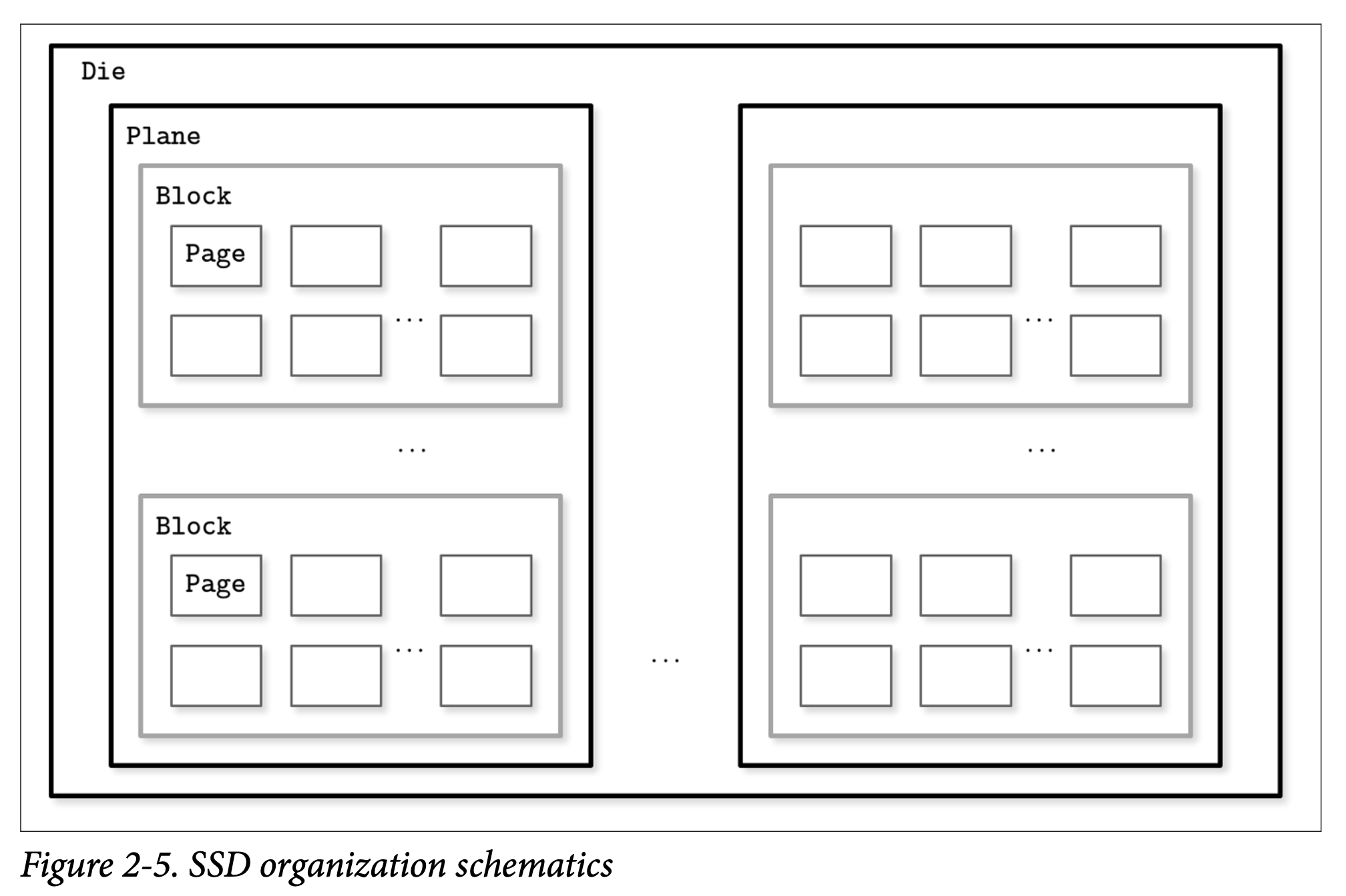
SSD: the smallest unit can be written or read is page (2 to 16 Kb), it should be erased before writing, the smallest erase entity isn’t a page, but a block that hold multiple pages (64 to 512 pages), pages in an empty block have to be written sequentially.
Writing only full blocks, and combining subsequent writes to the same block, can help to reduce the number of required I/O operations.
Compared with BST, B-Tree increases node fanout, and reduce the tree height, the number of node pointers, and the frequency of balancing operations.
Ubiquitous B-Trees
node splits:
- allocate a new node
- copy half the elements from the splitting node to the new one
- place the new element into the corresponding node
- at the parent of the split node, add a separator key and a pointer to the new node
[To Be Replaced with Better Contents]